Multimodal LLM 기초: LLM이 텍스트, 이미지, 오디오, 비디오를 처리하는 방법
원문: Multimodal LLMs Basics: How LLMs Process Text, Images, Audio & Videos
오랜 기간 동안 AI 시스템은 단일 감각에 국한된 전문가였습니다. 예를 들어:
- Computer vision 모델은 사진에서 객체를 식별할 수 있었지만, 그것이 무엇인지 설명할 수 없었습니다.
- Natural language processing 시스템은 유려한 산문을 작성할 수 있었지만 이미지를 볼 수 없었습니다.
- 오디오 처리 모델은 음성을 텍스트로 변환할 수 있었지만 시각적 맥락이 없었습니다.
이러한 분산은 인간이 세상을 경험하는 방식과는 근본적으로 다릅니다. 인간의 인지는 본질적으로 multimodal입니다. 우리는 단순히 텍스트만 읽거나 이미지만 보지 않습니다. 우리는 음성의 톤을 들으면서 동시에 표정을 관찰합니다. 개의 시각적 형태를 짖는 소리, 그리고 "dog"라는 단어와 연결합니다.
실제 세계에서 작동하는 AI를 만들기 위해서는 이러한 분리된 감각 채널들이 수렴되어야 했습니다.
Multimodal Large Language Model은 이러한 수렴을 나타냅니다. 예를 들어, GPT-4o는 음성 입력에 단 232밀리초만에 응답할 수 있어 인간의 대화 속도와 일치합니다. Google의 Gemini는 한 시간 분량의 비디오를 단일 프롬프트에서 처리할 수 있습니다.
이러한 기능은 동시에 보고, 듣고, 읽을 수 있는 단일 통합 신경망에서 나타납니다.
그렇다면 단일 AI 시스템이 어떻게 근본적으로 다른 유형의 데이터를 이해할까요? 이 글에서 우리는 이 질문에 답하려고 합니다.
공유된 수학적 언어
Multimodal LLM의 핵심 혁신은 매우 간단합니다. 텍스트, 이미지, 오디오 등 모든 유형의 입력은 embedding vector라는 동일한 유형의 수학적 표현으로 변환됩니다. 인간의 뇌가 빛 광자, 음파, 그리고 문자 기호를 균일한 신경 신호로 변환하는 것처럼, multimodal LLM은 다양한 데이터 타입을 동일한 수학적 공간을 차지하는 벡터로 변환합니다.
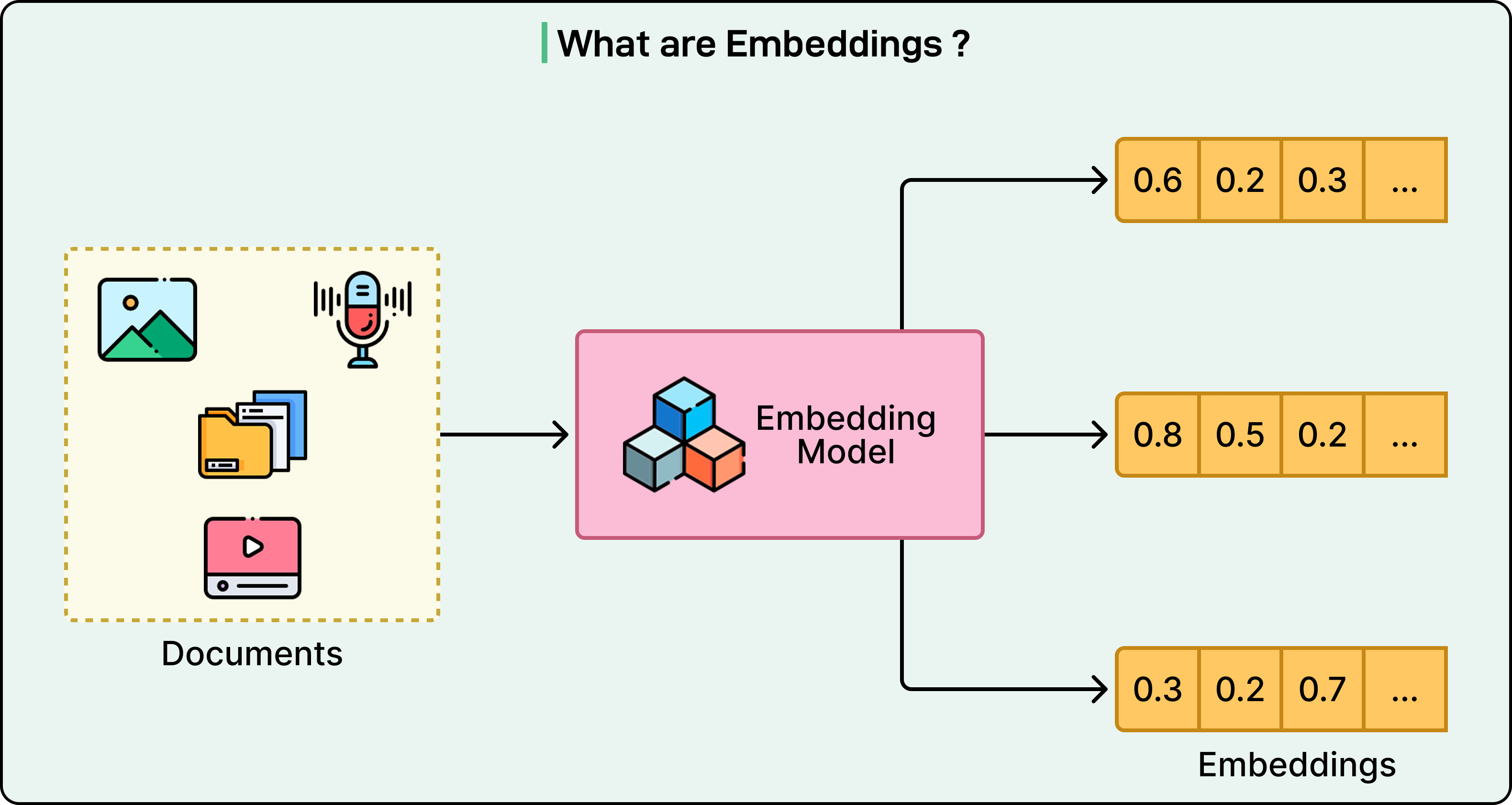
구체적인 예를 생각해봅시다. 개의 사진, "dog"라는 음성 단어, 그리고 "dog"라는 텍스트는 모두 고차원 수학적 공간의 점으로 변환됩니다. 이 점들은 같은 개념을 나타내기 때문에 서로 가깝게 군집화됩니다.
이 통합된 표현은 연구자들이 cross-modal reasoning이라고 부르는 것을 가능하게 합니다. 모델은 짖는 소리, 골든 리트리버의 사진, 그리고 "the dog is happy"라는 문장이 모두 동일한 기본 개념과 관련되어 있음을 이해할 수 있습니다. 모델은 각 modality에 대해 별도의 시스템이 필요하지 않습니다. 대신, 시각적 패치와 오디오 세그먼트를 텍스트 토큰처럼 처리하는 단일 아키텍처를 통해 모든 것을 처리합니다.
3부분 아키텍처: Multimodal LLM의 구성 요소
아래 다이어그램은 multimodal LLM의 작동 방식에 대한 상위 수준 뷰를 보여줍니다:
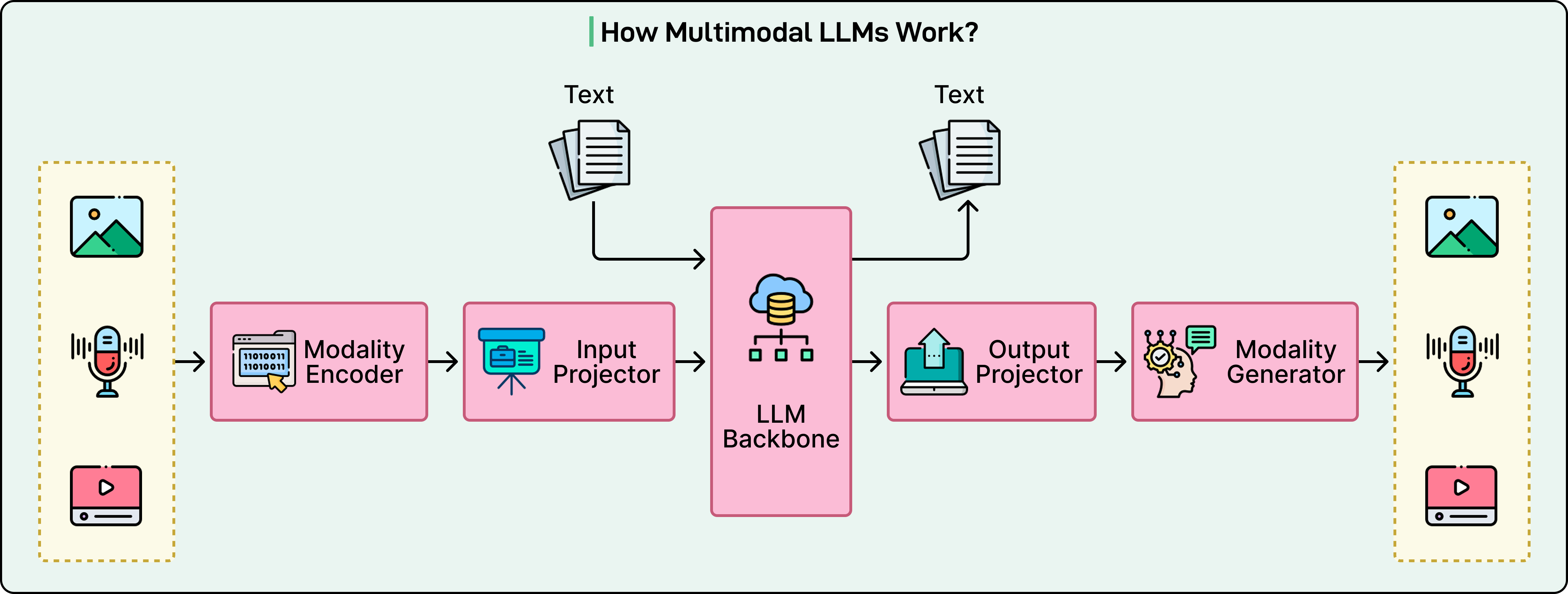
현대의 multimodal LLM은 다양한 입력을 처리하기 위해 함께 작동하는 세 가지 필수 구성 요소로 이루어져 있습니다.
Modality-Specific Encoder
첫 번째 구성 요소는 원시 감각 데이터를 초기 수학적 표현으로 변환하는 작업을 처리합니다.
- Vision Transformer는 이미지를 문장처럼 처리하여 사진을 작은 패치로 나누고 각 패치를 단어인 것처럼 처리합니다.
- Audio encoder는 음파를 spectrogram으로 변환하는데, 이는 시간에 따른 주파수 변화를 보여주는 시각적 표현입니다.
이러한 encoder는 일반적으로 대규모 데이터셋에서 사전 학습되어 특정 작업에 매우 능숙해집니다.
Projection Layer: 번역기
두 번째 구성 요소는 다리 역할을 합니다. 두 encoder 모두 벡터를 생성하지만, 이러한 벡터는 서로 다른 수학적 공간에 존재합니다. 즉, vision encoder의 "cat" 표현은 language model의 "cat"이라는 단어의 표현과는 다른 기하학적 영역에 있습니다.
Projection layer는 이러한 다른 표현들을 language model이 작동하는 공유 공간으로 정렬합니다. 종종 이러한 projector는 놀랍도록 간단하며, 때로는 단순한 선형 변환이나 작은 2층 신경망일 뿐입니다. 단순함에도 불구하고, 이들은 모델이 시각적 및 청각적 개념을 이해할 수 있게 하는 데 중요합니다.
Language Model Backbone
세 번째 구성 요소는 GPT나 LLaMA와 같은 핵심 LLM입니다.
이것은 실제 추론을 수행하고 응답을 생성하는 "두뇌"입니다. 모든 입력을 토큰 시퀀스로 받으며, 이러한 토큰이 텍스트, 이미지 패치 또는 오디오 세그먼트에서 비롯되었든 상관없습니다.
Language model은 모든 것을 동일하게 처리하며, 텍스트 전용 모델을 구동하는 동일한 transformer 아키텍처를 통해 모든 것을 처리합니다. 이 통합 처리는 모델이 순수 텍스트를 처리하는 것처럼 자연스럽게 modality 간에 추론할 수 있게 합니다.
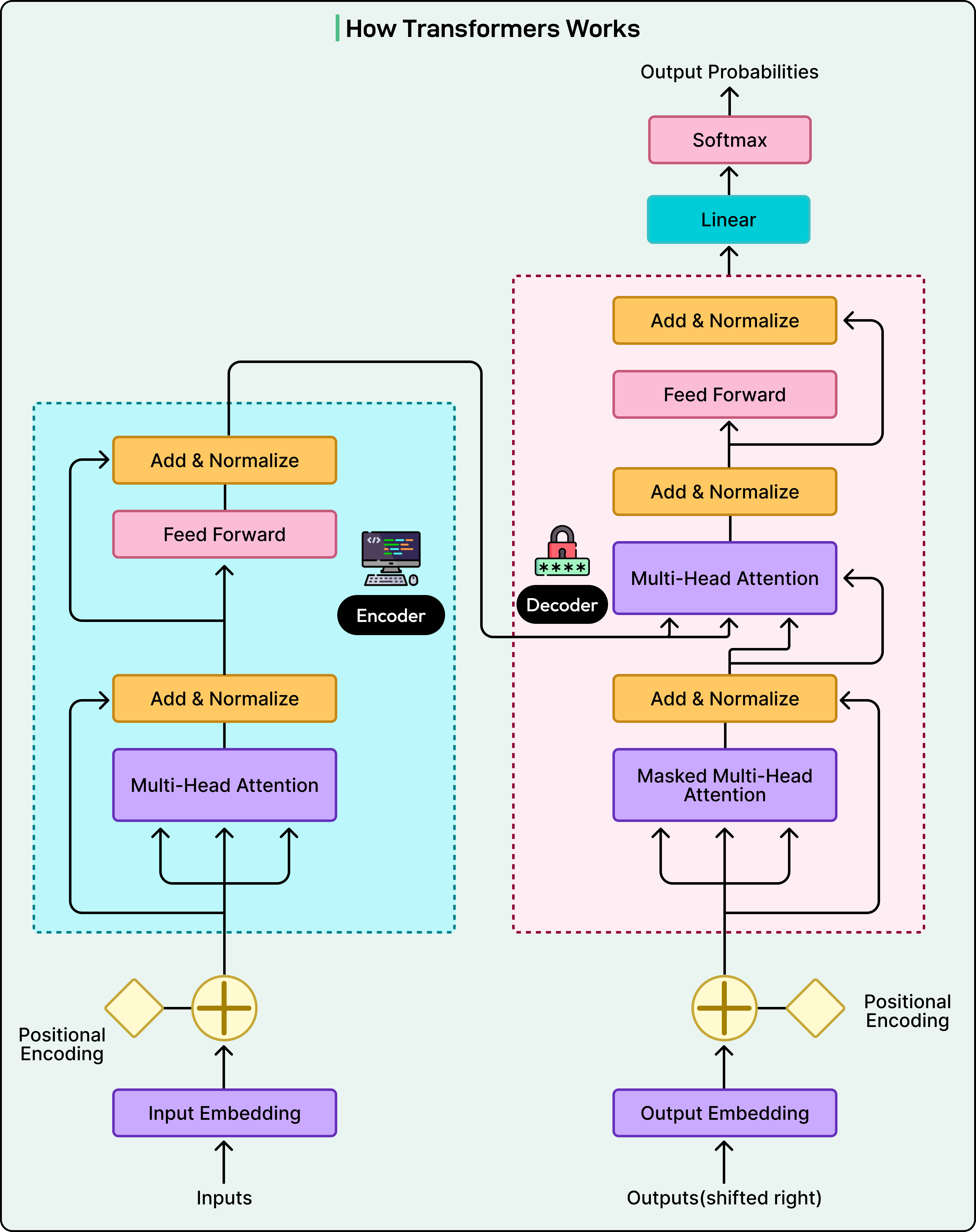
아래 다이어그램은 transformer 아키텍처를 보여줍니다:
이미지가 LLM이 이해할 수 있는 것이 되는 방법
현대 multimodal vision을 가능하게 한 혁신은 기억에 남는 제목을 가진 2020년 논문에서 나왔습니다: "An Image is Worth 16x16 Words." 이 논문은 작은 패치를 토큰으로 처리하여 이미지를 문장처럼 처리하는 아이디어를 소개했습니다.
프로세스는 여러 단계를 통해 작동합니다:
- 먼저, 이미지는 고정 크기 패치의 그리드로 나뉩니다. 일반적으로 각각 16x16 픽셀입니다.
- 표준 224x224 픽셀 이미지는 약 196개의 개별 패치가 되며, 각각은 작은 정사각형 영역을 나타냅니다.
- 각 패치는 2D 그리드에서 픽셀 강도를 나타내는 숫자의 1D 벡터로 평탄화됩니다.
- Positional embedding이 추가되어 모델이 각 패치가 원본 이미지에서 어디에서 왔는지 알 수 있습니다.
- 이러한 패치 embedding은 transformer 레이어를 통해 흐르며, attention mechanism은 패치가 서로 학습할 수 있게 합니다.
Attention mechanism은 이해가 나타나는 곳입니다. 개의 귀를 보여주는 패치는 개의 얼굴과 몸을 보여주는 인근 패치와 연결되는 것을 학습합니다. 해변 장면을 묘사하는 패치는 모래와 물의 더 넓은 맥락을 나타내기 위해 서로 연관되는 것을 학습합니다. 최종 레이어에서 이러한 시각적 토큰은 풍부한 맥락 정보를 전달합니다. 모델은 단순히 "갈색 픽셀"을 보는 것이 아니라 "해변에 앉아 있는 골든 리트리버"를 이해합니다.
OpenAI CLIP
두 번째 중요한 혁신은 OpenAI가 개발한 CLIP입니다. CLIP은 근본적인 목표를 변경하여 vision encoder가 학습되는 방식을 혁신했습니다. 라벨링된 이미지 카테고리에서 학습하는 대신, CLIP은 인터넷의 4억 쌍의 이미지와 텍스트 캡션에서 학습되었습니다.
CLIP은 contrastive learning 접근 방식을 사용합니다. 이미지-텍스트 쌍의 배치가 주어지면, 모든 이미지와 모든 텍스트 설명에 대한 embedding을 계산합니다. 목표는 올바른 이미지-텍스트 쌍의 embedding 간 유사성을 최대화하는 동시에 잘못된 쌍 간의 유사성을 최소화하는 것입니다. 개의 이미지는 "공원에 있는 개"라는 캡션에 가까운 벡터를 생성해야 하지만 "파스타 접시"와는 멀어야 합니다.
오디오가 이해 가능해지는 방법
오디오는 language model에 고유한 도전 과제를 제시합니다.
자연스럽게 개별 단어로 나뉘는 텍스트나 공간적 패치로 나눌 수 있는 이미지와 달리, 소리는 연속적이고 시간적입니다. 예를 들어, 16,000 Hz로 샘플링된 30초 오디오 클립에는 480,000개의 개별 데이터 포인트가 포함됩니다. 이 방대한 숫자 스트림을 transformer에 직접 공급하는 것은 계산적으로 불가능하고 비효율적입니다. 해결책은 오디오를 더 다루기 쉬운 표현으로 변환하는 것을 요구합니다.
핵심 혁신은 오디오를 spectrogram으로 변환하는 것입니다. 이는 본질적으로 소리의 이미지입니다. 프로세스는 여러 수학적 변환을 포함합니다:
- 긴 오디오 신호는 일반적으로 각각 25밀리초씩 작은 중첩 윈도우로 잘립니다.
- Fast Fourier Transform이 각 윈도우에 존재하는 주파수를 추출합니다.
- 이러한 주파수는 mel scale에 매핑되며, 이는 낮은 주파수에 더 많은 해상도를 제공하여 인간의 청각 민감도와 일치합니다.
- 결과는 시간이 한 축을 따라 실행되고, 주파수가 다른 축을 따라 실행되며, 색상 강도가 볼륨을 나타내는 2D heat map입니다.
이 mel-spectrogram은 AI 모델에게 이미지처럼 보입니다. 30초 클립의 경우, 이것은 80x3,000 그리드를 생성할 수 있으며, 이는 본질적으로 사진과 유사하게 처리될 수 있는 음향 패턴의 시각적 표현입니다.
오디오가 spectrogram으로 변환되면, 모델은 vision에 사용되는 것과 동일한 기술을 적용할 수 있습니다. Audio Spectrogram Transformer는 이미지가 나뉘는 것처럼 spectrogram을 패치로 나눕니다. 예를 들어, 680,000시간의 다국어 오디오에서 학습된 Whisper와 같은 모델은 이 변환에 뛰어납니다.
학습 프로세스
학습 프로세스는 다양한 단계를 거칩니다:
1단계: Feature Alignment
Multimodal LLM을 학습하는 것은 일반적으로 두 가지 별개의 단계에서 발생합니다.
첫 번째 단계는 순전히 정렬에 초점을 맞추며, 동일한 개념의 시각적 및 텍스트 표현이 유사해야 한다고 모델에 가르칩니다. 이 단계에서 사전 학습된 vision encoder와 사전 학습된 language model은 모두 고정된 상태로 유지됩니다. 학습을 통해 projection layer의 가중치만 업데이트됩니다.
2단계: Visual Instruction Tuning
정렬만으로는 실용적인 사용에 충분하지 않습니다. 모델은 이미지에 무엇이 있는지 설명할 수 있지만 "왜 그 사람이 슬퍼 보이는가?" 또는 "두 차트를 비교하라"와 같은 복잡한 작업에서 실패할 수 있습니다.
Visual instruction tuning은 모델이 정교한 multimodal 지시를 따르도록 학습시켜 이 문제를 해결합니다.
이 단계에서 projection layer는 계속 학습하고 language model도 종종 parameter-efficient 방법을 사용하여 업데이트됩니다. 학습 데이터는 대화로 형식화된 instruction-response 데이터셋으로 전환됩니다.
여기서 중요한 혁신은 GPT-4를 사용하여 합성 학습 데이터를 생성하는 것이었습니다. 연구자들은 GPT-4에 이미지의 텍스트 설명을 공급하고 해당 이미지에 대한 현실적인 대화를 생성하도록 프롬프트했습니다. 이 합성이지만 고품질 데이터에서 학습하면 GPT-4의 추론 기능을 multimodal 모델로 효과적으로 증류하여, 단순히 보는 것을 설명하는 것이 아니라 미묘한 시각적 대화에 참여하도록 가르칩니다.
결론
Multimodal LLM은 통합 원칙을 통해 놀라운 기능을 달성합니다. 모든 입력을 공유된 수학적 공간을 차지하는 embedding vector의 시퀀스로 변환함으로써, 단일 transformer 아키텍처는 언어만을 처리하는 것처럼 유창하게 modality 간에 추론할 수 있습니다.
이 기능을 구동하는 아키텍처 혁신은 진정한 발전을 나타냅니다: 이미지를 시각적 문장으로 처리하는 Vision Transformer, 명시적 라벨 없이 modality를 정렬하는 contrastive learning, 그리고 다양한 데이터 타입에 걸쳐 선택적 정보 검색을 가능하게 하는 cross-attention입니다.
미래는 모든 modality를 이해하고 생성할 수 있는 any-to-any 모델을 가리킵니다. 즉, 단일 응답에서 텍스트를 출력하고, 이미지를 생성하고, 음성을 합성하는 모델입니다.
Thank you for reading.