EP176: SSO는 어떻게 동작하는가?
이번 주 시스템 설계 복습:
-
SSO는 어떻게 동작하는가?
-
API 설계 모범 사례
-
Domain-Driven Design의 핵심 용어
-
알아두어야 할 주요 AI Agent Framework
-
OpenAI의 GPT-OSS 120B와 20B 모델은 어떻게 동작하는가?
-
ByteByteGo 기술 면접 준비 키트
SSO는 어떻게 동작하는가?
Single Sign-On (SSO)은 인증 체계입니다. 사용자가 하나의 ID로 여러 시스템에 로그인할 수 있도록 해줍니다.
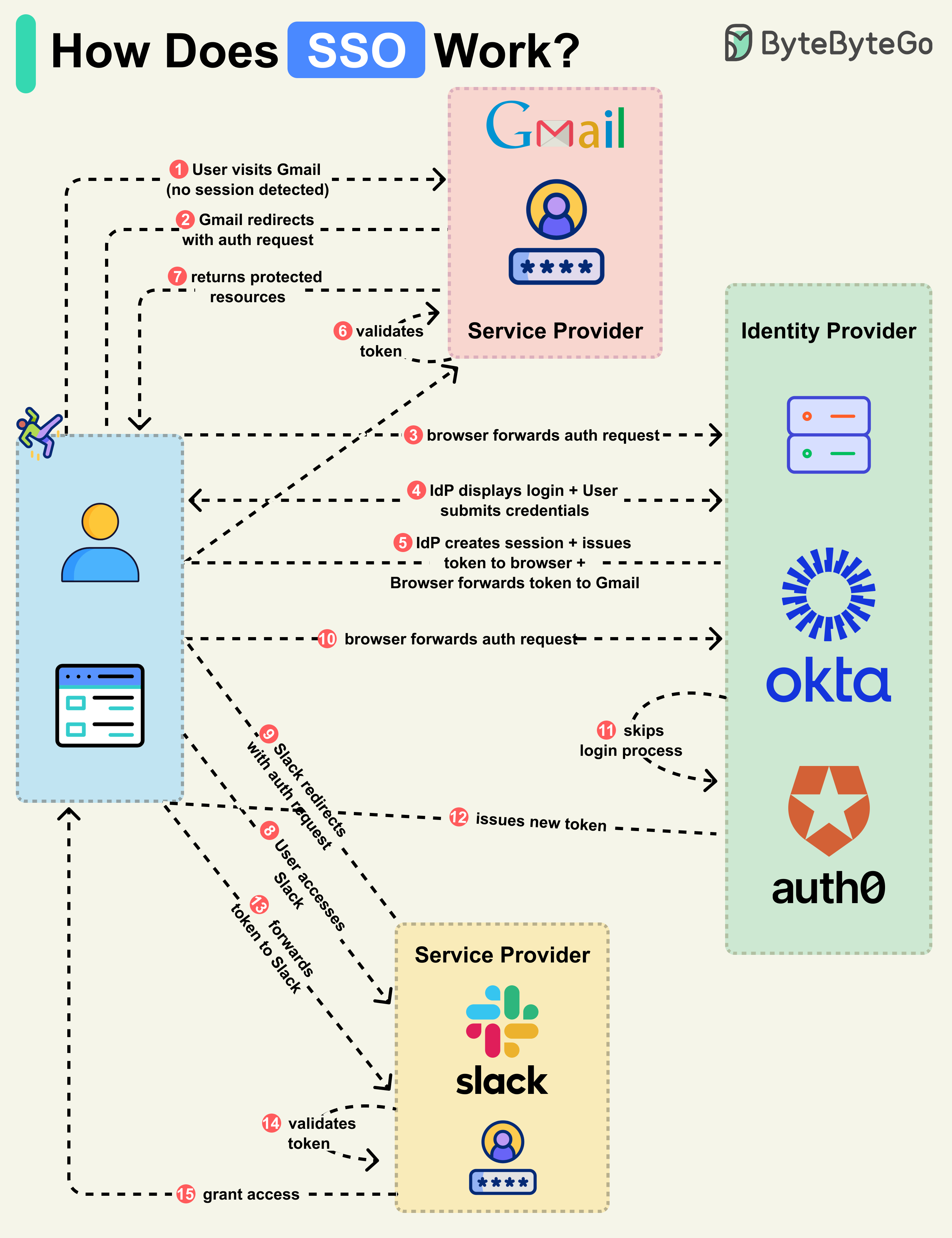
일반적인 SSO 로그인 플로우를 살펴보겠습니다:
Step 1: 사용자가 Service Provider(SP)인 Gmail과 같은 애플리케이션의 보호된 리소스에 접근합니다.
Step 2: Gmail 서버는 사용자가 로그인되어 있지 않음을 감지하고, 인증 요청과 함께 브라우저를 회사의 Identity Provider(IdP)로 리다이렉트합니다.
Step 3: 브라우저가 사용자를 IdP로 보냅니다.
Step 4: IdP가 로그인 페이지를 보여주고, 사용자는 로그인 자격 증명을 입력합니다.
Step 5: IdP가 보안 토큰을 생성하여 브라우저에 반환합니다. IdP는 향후 접근을 위한 세션도 생성합니다. 브라우저는 이 토큰을 Gmail로 전달합니다.
Step 6: Gmail이 토큰이 IdP로부터 온 것인지 검증합니다.
Step 7: Gmail이 사용자가 접근 권한이 있는 보호된 리소스를 브라우저에 반환합니다.
이것으로 기본적인 SSO 로그인 플로우가 완료됩니다. 이제 사용자가 Slack과 같은 다른 SSO 통합 애플리케이션으로 이동할 때 어떤 일이 일어나는지 살펴보겠습니다.
Step 8-9: 사용자가 Slack에 접근하면, Slack 서버는 사용자가 로그인되어 있지 않음을 감지합니다. 새로운 인증 요청과 함께 브라우저를 IdP로 리다이렉트합니다.
Step 10: 브라우저가 사용자를 다시 IdP로 보냅니다.
Step 11-13: 사용자가 이미 IdP에 로그인했으므로, IdP는 로그인 과정을 건너뛰고 대신 Slack을 위한 새 토큰을 생성합니다. 새 토큰이 브라우저로 전송되고, 브라우저는 이를 Slack으로 전달합니다.
Step 14-15: Slack이 토큰을 검증하고 사용자에게 그에 따른 접근 권한을 부여합니다.
Over to you: 다른 애플리케이션에 대한 예시 플로우를 보고 싶으신가요?
API 설계 모범 사례

API는 인터넷상 통신의 근간입니다. 잘 설계된 API는 일관되게 동작하고, 예측 가능하며, 마찰 없이 확장됩니다. 명심해야 할 몇 가지 모범 사례는 다음과 같습니다:
-
명확한 네이밍 사용: API를 구축할 때 직관적이고 논리적인 이름을 선택하세요. 일관성을 유지하고 컬렉션을 나타내는 직관적인 URL을 사용하세요.
-
Idempotency: API는 idempotent해야 합니다. 반복된 요청이 동일한 결과를 생성하도록 하여 안전한 재시도를 보장합니다. 특히 POST 작업에서 중요합니다.
-
Pagination: API는 성능 병목 현상과 페이로드 비대화를 방지하기 위해 pagination을 지원해야 합니다. 일반적인 pagination 전략으로는 offset 기반과 cursor 기반이 있습니다.
-
Sorting과 Filtering: Query string은 API 응답의 정렬과 필터링을 허용하는 효과적인 방법입니다. 이를 통해 개발자가 어떤 필터와 정렬 순서가 적용되었는지 쉽게 확인할 수 있습니다.
-
Cross Resource References: 연결된 리소스 간에 명확한 링크를 사용하세요. API를 이해하기 어렵게 만드는 과도하게 긴 query string은 피하세요.
-
Rate Limiting: Rate limiting은 특정 시간 내에 사용자가 API에 보낼 수 있는 요청 수를 제어하는 데 사용됩니다. 이는 API의 신뢰성과 가용성을 유지하는 데 필수적입니다.
-
Versioning: API 엔드포인트를 수정할 때, 하위 호환성을 지원하기 위한 적절한 버전 관리가 중요합니다.
-
Security: API 보안은 잘 설계된 API에 필수입니다. API Key, JWT, OAuth2 및 기타 메커니즘을 사용하여 적절한 인증과 권한 부여를 구현하세요.
Over to you: 우리가 놓친 중요한 것이 있나요?
Domain-Driven Design의 핵심 용어
주요 소프트웨어 설계 접근 방식인 Domain-Driven Design(DDD)에 대해 들어보셨나요?
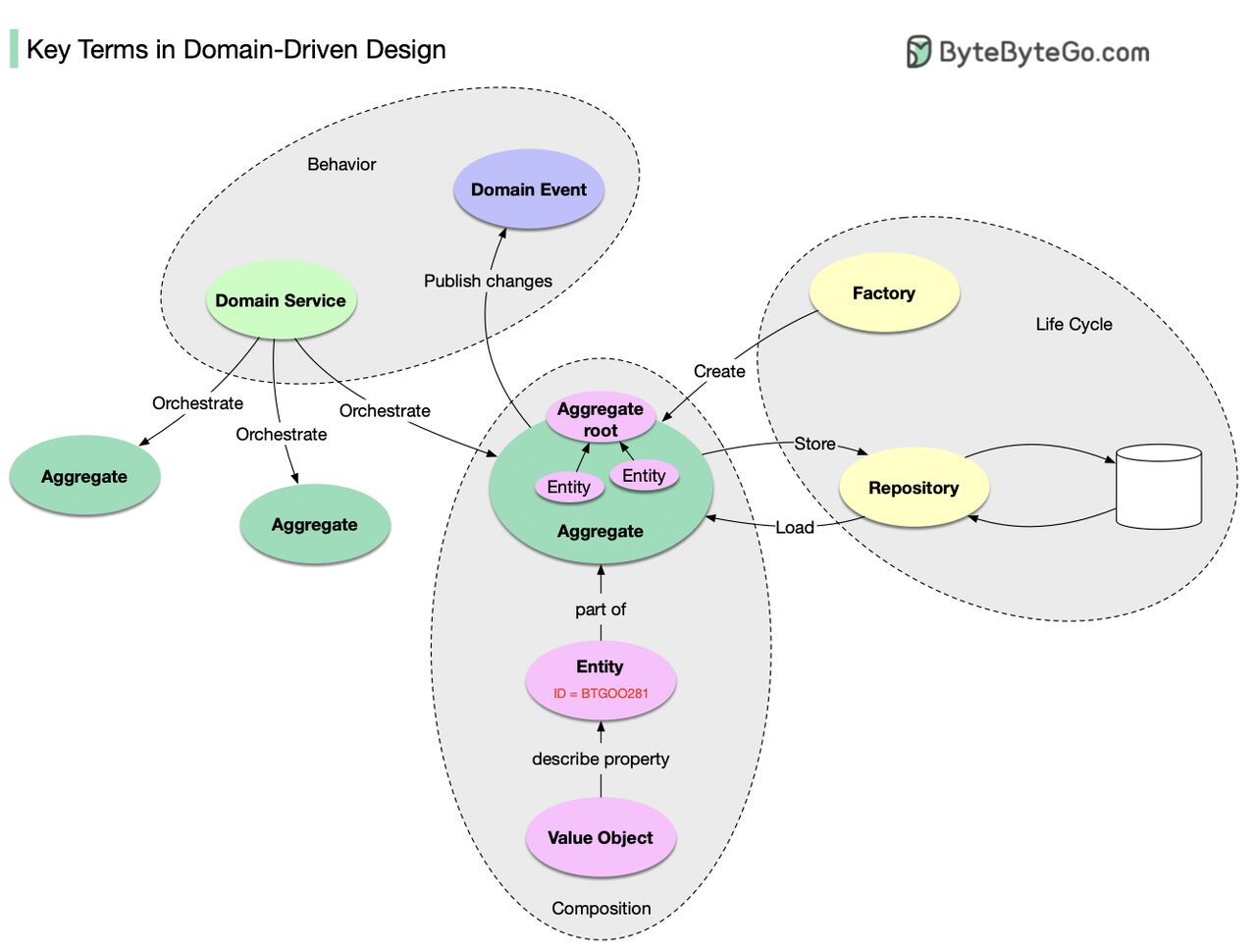
DDD는 Eric Evans의 명저 "Domain-Driven Design: Tackling Complexity in the Heart of Software"에서 소개되었습니다. 이 책은 복잡한 비즈니스를 모델링하는 방법론을 설명했습니다. 이 책에는 많은 내용이 있으므로, 기본 사항을 요약해 드리겠습니다.
도메인 객체의 구성:
-
Entity: ID와 생명주기를 가진 도메인 객체입니다.
-
Value Object: ID가 없는 도메인 객체입니다. Entity의 속성을 설명하는 데 사용됩니다.
-
Aggregate: Aggregate Root(이것도 entity임)에 의해 함께 묶인 Entity들의 집합입니다. 저장의 단위입니다.
도메인 객체의 생명주기:
-
Repository: Aggregate를 저장하고 로드합니다.
-
Factory: Aggregate의 생성을 처리합니다.
도메인 객체의 행위:
-
Domain Service: 여러 Aggregate를 조율합니다.
-
Domain Event: Aggregate에 발생한 일에 대한 설명입니다. 다른 사람들이 소비하고 재구성할 수 있도록 공개적으로 발행됩니다.
여기까지 오신 것을 축하드립니다. 이제 DDD의 기본을 아시게 되었습니다. 더 배우고 싶으시다면, 이 책을 강력히 추천합니다. 소프트웨어 모델링의 복잡성을 단순화하는 데 도움이 될 수 있습니다.
Over to you: 두 Value Object의 동등성을 확인하는 방법을 아시나요? 두 Entity는 어떨까요?
알아두어야 할 주요 AI Agent Framework
스마트하고 독립적인 AI 시스템을 구축하는 것은 대규모 언어 모델(LLM)을 API, 웹 접근, 코드 실행과 같은 도구와 결합하는 agent framework를 사용하면 더 쉬워집니다.
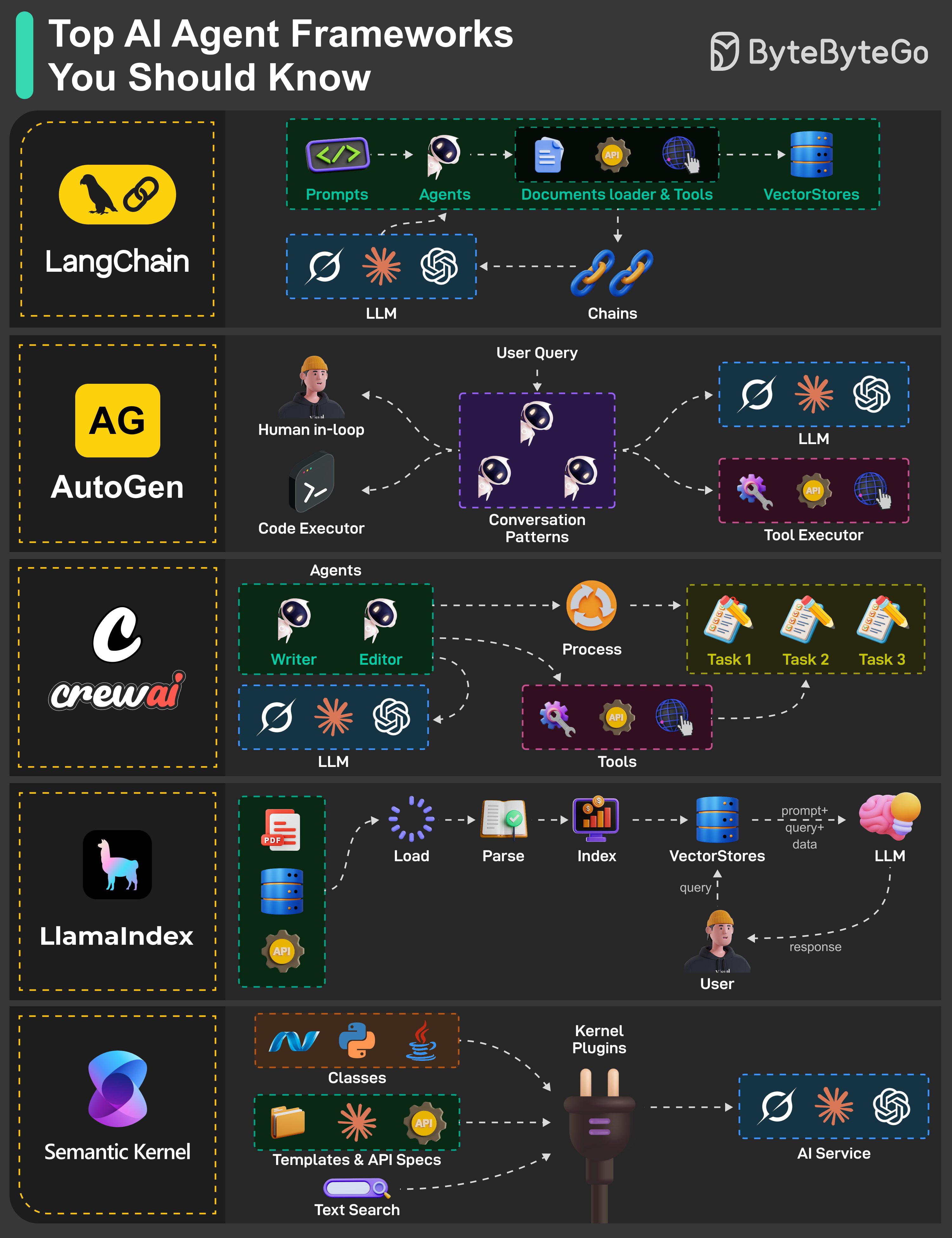
LangChain
LangChain은 LLM을 API 및 vector database와 같은 외부 도구와 연결하는 것을 간단하게 만들어줍니다. 개발자가 순차적 작업 실행을 위한 chain과 context-aware 응답을 위한 document loader를 생성할 수 있게 해줍니다.
AutoGen
AutoGen을 사용하면 서로 대화하거나 human-in-the-loop를 포함할 수 있는 AI agent를 개발할 수 있습니다. agent들이 코드를 실행하고, 도구에서 데이터를 가져오거나, 작업을 완료하기 위해 인간의 피드백을 받을 수 있는 협업 작업 공간과 같습니다.
CrewAI
이름에서 알 수 있듯이, CrewAI는 팀워크에 관한 것입니다. writer와 editor 같은 역할을 가진 AI agent 팀을 조율하여 구조화된 워크플로우로 작업을 처리합니다. LLM과 도구(API, 인터넷, 코드 등)를 활용하여 복잡한 작업 실행과 데이터 흐름을 효율적으로 관리합니다.
LlamaIndex
이 framework는 문서, API, vector store의 데이터를 인덱싱하고 쿼리하여 agent 응답을 향상시킵니다. 데이터를 파싱하고 로드하여 LLM이 context-aware 답변을 제공할 수 있게 하므로, 엔터프라이즈 문서 검색 시스템과 비공개 지식 기반에 접근하는 지능형 어시스턴트에 이상적입니다.
Semantic Kernel
Semantic Kernel은 AI 서비스(OpenAI, Claude, Hugging Face 모델 등)를 스킬, 템플릿, API 통합을 지원하는 플러그인 기반 아키텍처로 유연한 워크플로우와 연결합니다. 애플리케이션을 위한 텍스트 검색과 커스텀 워크플로우를 지원합니다.
Over to you: 어떤 AI agent framework를 탐색해보셨거나 사용할 계획이신가요?
OpenAI의 GPT-OSS 120B와 20B 모델은 어떻게 동작하는가?
OpenAI는 최근 두 개의 LLM을 출시했습니다: GPT-OSS-120B(1,200억 파라미터)와 GPT-OSS-20B(200억 파라미터). 이들은 완전한 오픈소스 모델로, Apache 2.0 라이선스로 제공됩니다.
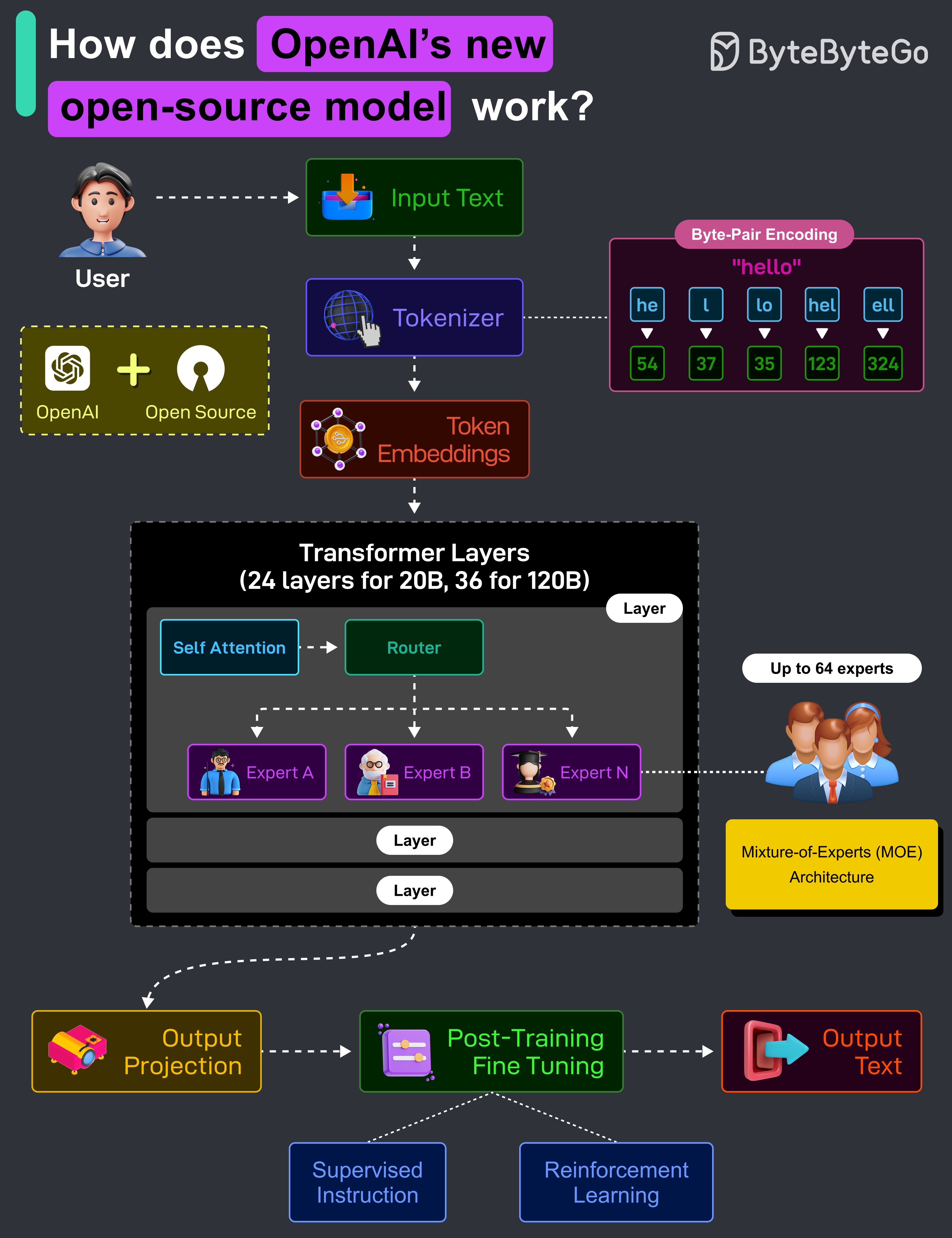
이 모델들은 저비용으로 강력한 실제 성능을 제공하는 것을 목표로 합니다. 동작 방식은 다음과 같습니다:
-
사용자가 질문이나 작업 같은 입력을 제공합니다. 예를 들어, "양자역학을 간단하게 설명해줘".
-
원시 텍스트는 Byte-Pair Encoding(BPE)을 사용하여 숫자 토큰으로 변환됩니다. BPE는 텍스트를 자주 등장하는 subword 단위로 분할합니다. 바이트 수준에서 작동하므로 텍스트, 코드, 이모지 등 모든 입력을 처리할 수 있습니다.
-
각 토큰은 학습된 embedding 테이블을 사용하여 벡터(숫자 목록)로 매핑됩니다. 이 벡터화된 형태가 모델이 이해하고 처리하는 것입니다.
-
Transformer 레이어에서 실제 계산이 이루어집니다. 20B 모델은 24개의 Transformer 레이어를, 120B 모델은 36개의 Transformer 레이어를 가지고 있습니다. 각 레이어에는 self-attention 모듈, router, expert(MoE)가 포함됩니다.
-
Self-attention 모듈은 모델이 전체 입력에 걸쳐 단어 간의 관계를 이해할 수 있게 합니다.
-
이 LLM은 Mixture-of-Experts(MOE) 아키텍처를 사용합니다. 전통적인 모델처럼 모든 모델 가중치를 사용하는 대신, router가 총 64개의 expert 풀에서 가장 적합한 2개의 "expert"를 선택합니다. 각 expert는 특정 유형의 입력에 특화되도록 훈련된 작은 feedforward 네트워크입니다. 토큰당 2개의 expert만 활성화되므로, 품질을 향상시키면서 계산을 절약합니다.
-
모든 레이어를 통과한 후, 모델은 내부 표현을 다시 토큰 확률로 투영하여 다음 단어나 구문을 예측합니다.
-
원시 모델을 안전하고 유용하게 만들기 위해, supervised fine-tuning과 reinforcement learning을 거칩니다.
-
마지막으로, 모델은 예측된 토큰을 기반으로 응답을 생성하여, context에 기반한 일관된 출력을 사용자에게 반환합니다.
Over to you: OpenAI의 오픈소스 모델을 사용해 보셨나요?
Reference: Introducing gpt-oss | OpenAI
ByteByteGo 기술 면접 준비 키트
올인원 면접 준비를 시작합니다. 모든 책을 ByteByteGo 웹사이트에서 이용할 수 있게 되었습니다.
포함된 내용:
-
System Design Interview
-
Coding Interview Patterns
-
Object-Oriented Design Interview
-
How to Write a Good Resume
-
Behavioral Interview (곧 출시)
-
Machine Learning System Design Interview
-
Generative AI System Design Interview
-
Mobile System Design Interview
-
And more to come
Related Articles
Thank you for reading.