EP169: RAG vs Agentic RAG
이번 주 시스템 설계 복습:
- 7가지 시스템 설계 개념을 10분만에 설명 (Youtube 영상)
- RAG vs Agentic RAG
- Kubernetes 치트시트
- 스토리지 절약을 위한 6가지 데이터 구조
- 모든 개발자가 알아야 할 5가지 데이터베이스 정규형
- 채용 정보
- 스폰서 안내
7가지 시스템 설계 개념을 10분만에 설명
(YouTube 영상)
RAG vs Agentic RAG

RAG(Retrieval Augmented Generation)는 정보 검색과 대형 언어 모델을 결합하여 답변을 생성하는 방식입니다. RAG가 높은 수준에서 어떻게 작동하는지 살펴보겠습니다:
- 모델은 데이터 소스에서 관련 데이터를 검색한 다음, 사전 인덱싱된 모델에서 vector database로 추출합니다.
- 검색된 정보를 가져와 쿼리 프롬프트와 병합하여 프롬프트를 보강합니다.
- 대형 언어 모델(GPT, Claude, Gemini 등)이 결합된 쿼리를 이해하고 최종 응답을 생성합니다.
기존 RAG는 단순한 검색 방식, 제한된 적응성, 정적 지식에 의존하기 때문에 동적이고 실시간 정보에 대해서는 유연성이 떨어집니다.
Agentic RAG는 의사결정을 내리고, 도구를 선택하며, 쿼리를 정제하여 더 정확하고 유연한 응답을 제공할 수 있는 AI agent를 도입하여 이를 개선합니다. Agentic RAG가 높은 수준에서 어떻게 작동하는지 살펴보겠습니다:
- 사용자 쿼리는 처리를 위해 AI Agent로 전달됩니다.
- agent는 쿼리 컨텍스트를 추적하기 위해 단기 및 장기 메모리를 사용합니다. 또한 검색 전략을 수립하고 작업에 적합한 도구를 선택합니다.
- 데이터 가져오기 프로세스는 vector search, 다중 agent, MCP 서버 등의 도구를 사용하여 지식 베이스에서 관련 데이터를 수집할 수 있습니다.
- 그런 다음 agent는 검색된 데이터를 쿼리 및 시스템 프롬프트와 결합합니다. 이 데이터를 LLM에 전달합니다.
- LLM은 최적화된 입력을 처리하여 사용자의 쿼리에 답변합니다.
Over to you: RAG와 Agentic RAG를 더 잘 이해하기 위해 무엇을 추가하시겠습니까?
Kubernetes 치트시트
Kubernetes(K8S)는 원래 Google이 개발하고 현재는 Cloud Native Computing Foundation(CNCF)에서 관리하는 오픈소스 컨테이너 오케스트레이션 플랫폼입니다.

Kubernetes로 작업하는 개발자들은 애플리케이션을 설명하고 인스턴스 수, 리소스 요구사항 및 기타 설정을 지정하는 manifest 파일을 생성합니다.
Kubernetes는 control plane과 노드 그룹을 사용하여 작동합니다. control plane은 master 노드에 배포되며 클러스터의 전체 상태를 관리합니다. API Server, Etcd, Controller Manager, Scheduler와 같은 구성 요소로 이루어져 있습니다.
노드는 Kubernetes 클러스터의 worker입니다. 각 노드에는 Kubelet과 Kube-proxy와 같은 구성 요소가 포함되어 있으며 컨테이너화된 애플리케이션을 실행하는 역할을 담당합니다.
Kubernetes의 주요 리소스로는 Pod, Deployment, Service, Persistent Volume이 있습니다.
- Pod는 하나 이상의 컨테이너를 캡슐화합니다.
- Deployment는 Pod를 관리하는 상위 수준의 추상화입니다.
- Service는 Pod 집합을 노출하고 접근하는 안정적인 방법을 제공하는 추상화입니다.
- Volume은 pod 재시작이나 재생성 사이에 데이터를 유지하는 데 도움이 되는 스토리지 리소스입니다.
Horizontal Pod Autoscaler는 관찰된 CPU 사용률, 메모리 사용량 또는 커스텀 메트릭을 기반으로 Deployment, ReplicaSet 또는 StatefulSet의 Pod 수를 스케일링하는 데 도움을 줍니다. 리소스 사용량을 모니터링하고 원하는 리소스 목표에 맞게 레플리카 수를 조정합니다.
Over to you: 프로젝트에서 Kubernetes를 사용해 보셨나요?
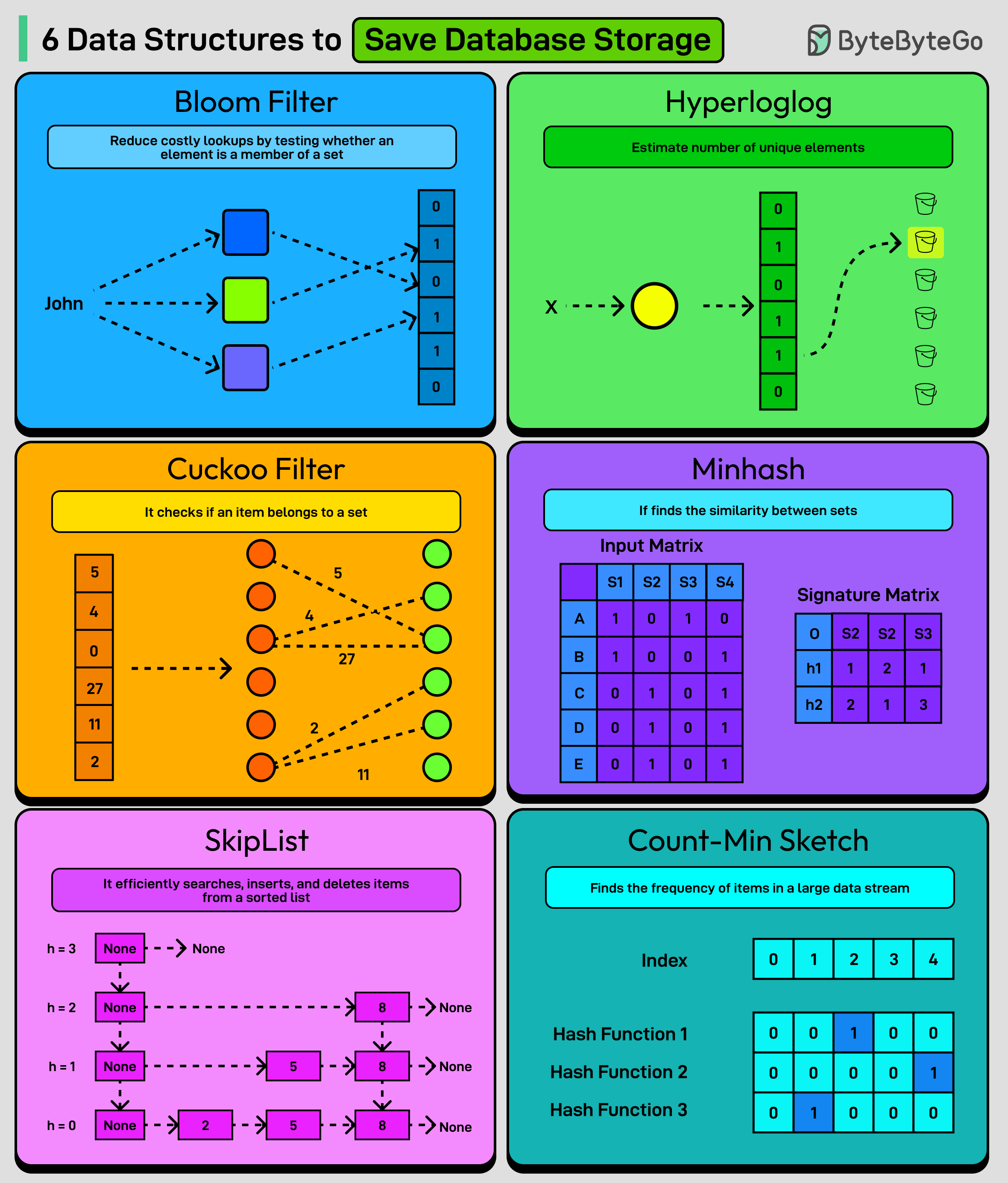
스토리지 절약을 위한 6가지 데이터 구조
-
Bloom Filter 요소가 집합의 멤버인지 테스트하는 데 사용되는 확률적 데이터 구조입니다.
-
HyperLogLog 최소한의 메모리를 사용하여 다중 집합의 고유 요소 수를 근사하는 알고리즘입니다.
-
Cuckoo Filter 삭제를 지원하고 더 나은 조회 성능을 가진 Bloom Filter의 공간 효율적인 대안입니다.
-
Minhash 압축된 해시 시그니처를 사용하여 대규모 집합 간의 유사도를 빠르게 추정하는 기법입니다.
-
SkipList 빠른 검색, 삽입, 삭제 연산을 허용하는 계층화된 연결 리스트 구조입니다.
-
Count-Min Sketch 대규모 데이터 스트림에서 항목의 빈도를 근사하는 확률적 데이터 구조입니다.
Over to you: 리스트에 어떤 다른 데이터 구조를 추가하시겠습니까?
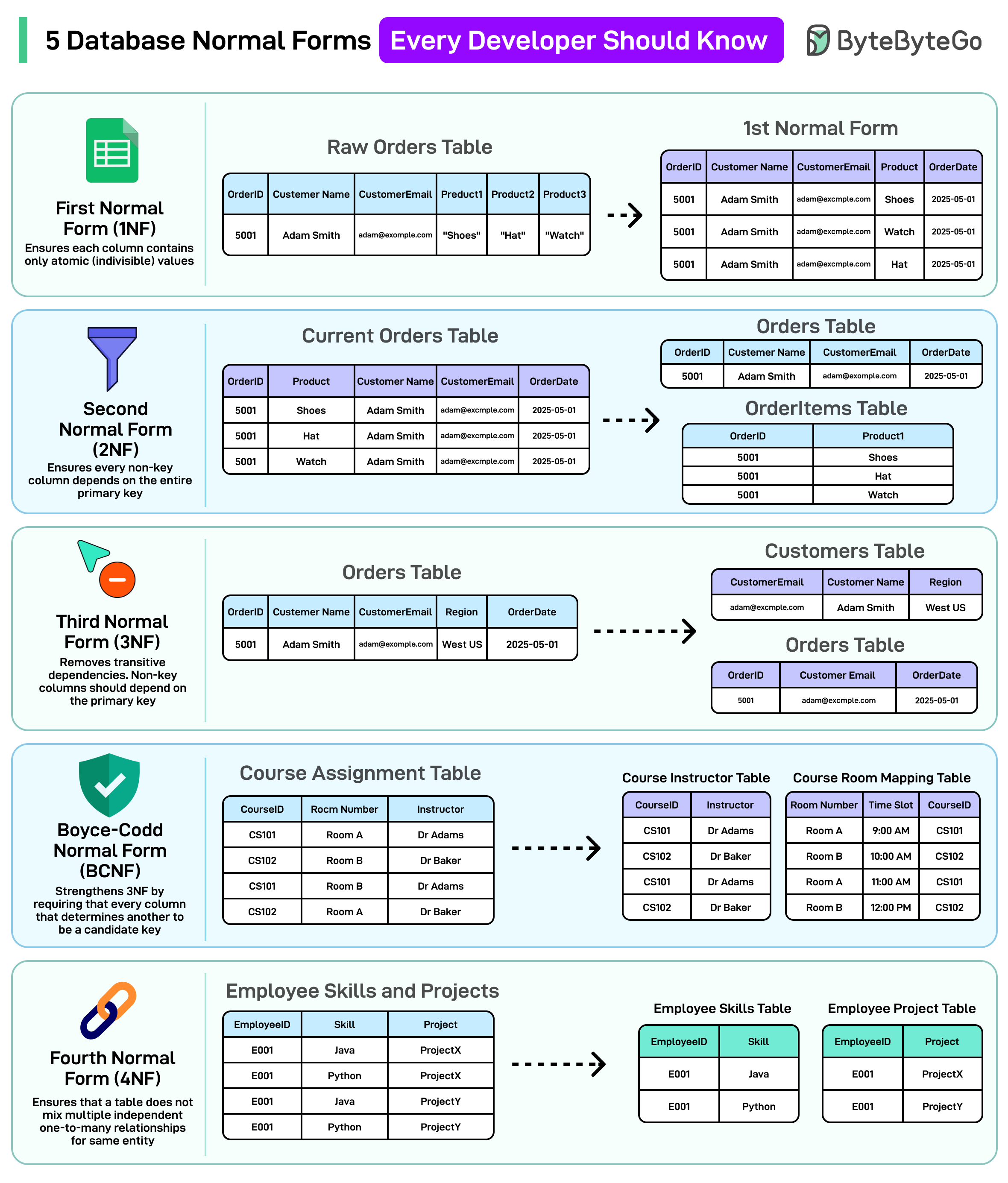
모든 개발자가 알아야 할 5가지 데이터베이스 정규형
정규화는 데이터를 논리적이고 종속성 기반의 형태로 구성하여 중복을 제거하고 데이터 무결성을 강화하는 것을 목표로 합니다.
-
제1정규형(1NF): 반복 그룹을 제거하고 각 컬럼에 원자 값을 보장합니다.
-
제2정규형(2NF): 모든 비키 컬럼이 전체 기본 키에 종속되도록 하여 부분 종속성을 제거합니다.
-
제3정규형(3NF): 이행적 종속성을 제거하여 비키 컬럼이 기본 키에만 종속되도록 합니다.
-
보이스-코드 정규형(BCNF): 중복되는 후보 키로 인해 존재하는 이상 현상을 제거하여 3NF를 강화합니다. 한 컬럼이 다른 컬럼에 종속된다면, 그 "다른 컬럼"은 각 행을 고유하게 식별할 수 있어야 합니다.
-
제4정규형(4NF): 테이블이 동일 엔티티에 대해 여러 독립적인 일대다 관계를 혼합하지 않도록 보장합니다.
Over to you: 리스트에 어떤 다른 정규형을 추가하시겠습니까?
Related Articles
Thank you for reading.