Claude Opus 4.5를 소개합니다
원문 출처: https://www.anthropic.com/news/claude-opus-4-5
2025년 11월 25일
오늘 최신 모델 Claude Opus 4.5를 공개합니다. 지능적이고 효율적이며, 코딩, 에이전트, 컴퓨터 사용 분야에서 세계 최고의 모델입니다. 딥 리서치, 슬라이드 및 스프레드시트 작업 같은 일상적인 업무에서도 눈에 띄게 향상되었습니다. Opus 4.5는 AI 시스템이 할 수 있는 일의 한 단계 도약이자, 업무 방식이 어떻게 바뀔지 보여주는 미리보기입니다.
Claude Opus 4.5는 실제 소프트웨어 엔지니어링 테스트에서 최고 수준의 성능을 보여줍니다:

Opus 4.5는 오늘부터 Claude 앱, API, 그리고 3대 클라우드 플랫폼 모두에서 사용 가능합니다. 개발자라면 Claude API에서 claude-opus-4-5-20251101을 사용하면 됩니다. 가격은 이제 입력 $5 / 출력 $25 (백만 토큰당)—Opus급 성능을 더 많은 사용자, 팀, 기업이 이용할 수 있게 되었습니다.
Opus와 함께 Claude Developer Platform, Claude Code, 그리고 소비자용 앱 업데이트도 함께 출시합니다. 장기 실행 에이전트를 위한 새로운 도구와 Excel, Chrome, 데스크톱에서 Claude를 사용하는 새로운 방법이 추가되었습니다. Claude 앱에서는 긴 대화가 더 이상 끊기지 않습니다. 자세한 내용은 아래 제품 섹션을 참조하세요.
첫인상
출시 전 Anthropic 동료들이 모델을 테스트하면서 놀라울 정도로 일관된 피드백을 받았습니다. 테스터들은 Claude Opus 4.5가 모호한 상황을 처리하고 트레이드오프를 추론할 때 일일이 가르쳐주지 않아도 된다고 했습니다. 복잡한 멀티시스템 버그를 던져주면 Opus 4.5가 알아서 수정 방법을 찾아낸다고 했습니다. 불과 몇 주 전까지 Sonnet 4.5로는 거의 불가능했던 작업들이 이제 가능해졌다고 했습니다. 전반적으로 테스터들은 Opus 4.5가 그냥 "알아서 한다(just gets it)"고 말했습니다.
얼리 액세스를 받은 많은 고객들도 비슷한 경험을 했습니다. 고객들이 전해준 이야기 몇 가지를 소개합니다:
Claude Opus 4.5 평가
우리는 퍼포먼스 엔지니어링 채용 후보자들에게 악명 높게 어려운 과제 시험을 줍니다. 또한 이 시험을 내부 벤치마크로 사용해 새 모델을 테스트합니다. 정해진 2시간 제한 내에서, **Claude Opus 4.5는 역대 어떤 인간 후보자보다도 높은 점수를 받았습니다.**¹
이 과제 시험은 시간 압박 속에서 기술적 능력과 판단력을 평가하도록 설계되었습니다. 협업, 커뮤니케이션, 또는 수년간의 경험을 통해 길러지는 직관 같은 다른 중요한 스킬은 테스트하지 않습니다. 하지만 이 결과—AI 모델이 중요한 기술 역량에서 강한 후보자들을 능가한 것—는 AI가 엔지니어링이라는 직업을 어떻게 바꿀지에 대한 질문을 제기합니다. 우리의 사회적 영향 및 경제적 미래(Societal Impacts and Economic Futures) 연구팀이 여러 분야에서 이런 변화를 이해하기 위해 연구하고 있습니다. 곧 더 많은 결과를 공유할 예정입니다.
소프트웨어 엔지니어링만 개선된 게 아닙니다. 전반적으로 역량이 높아졌습니다—Opus 4.5는 이전 모델보다 더 나은 비전, 추론, 수학 능력을 갖추고 있으며, 많은 영역에서 최고 수준입니다:²

-
SWE-bench Multilingual: Opus 4.5는 더 나은 코드를 작성하며, SWE-bench Multilingual의 8개 프로그래밍 언어 중 7개에서 1위입니다.
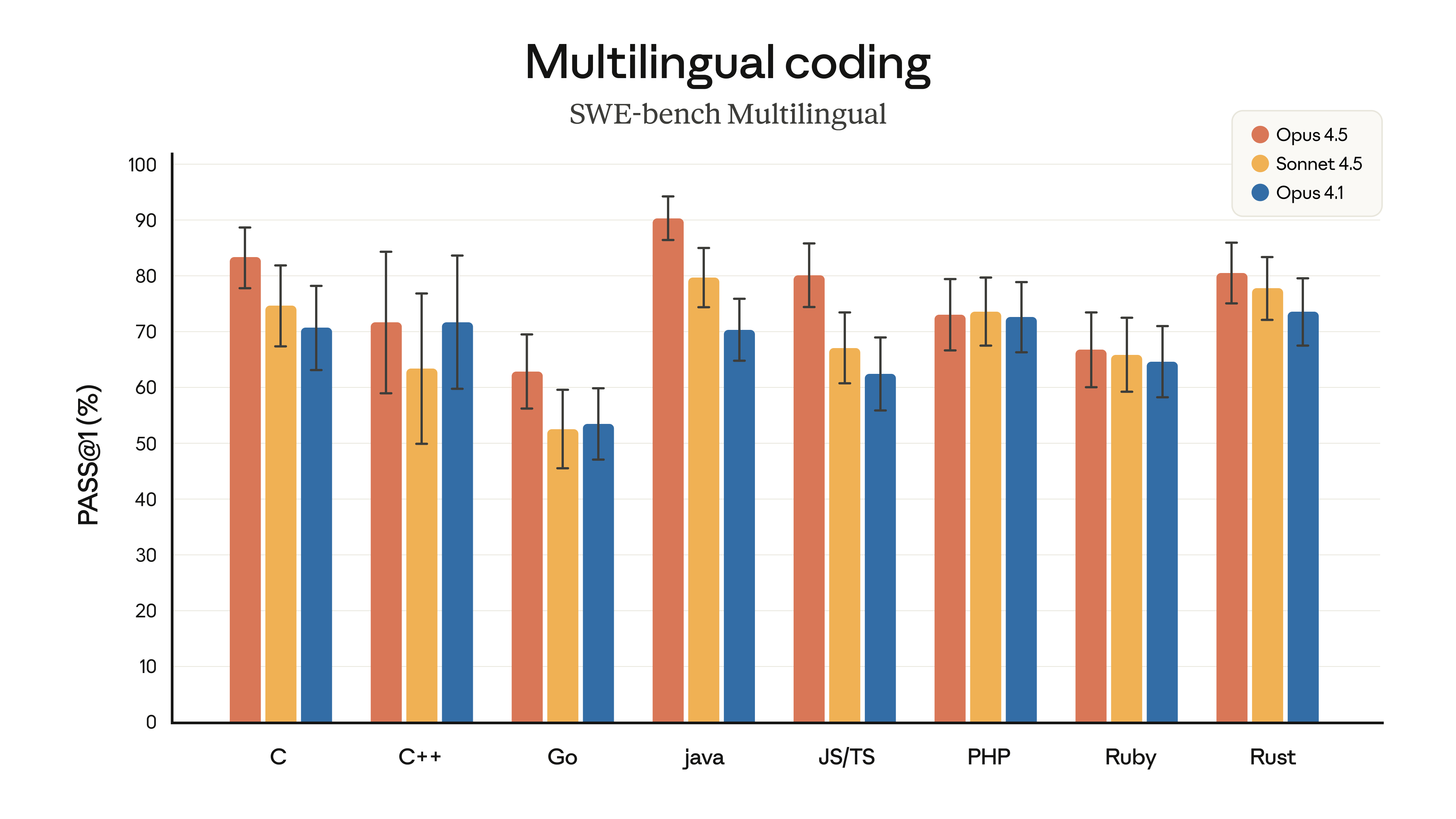
-
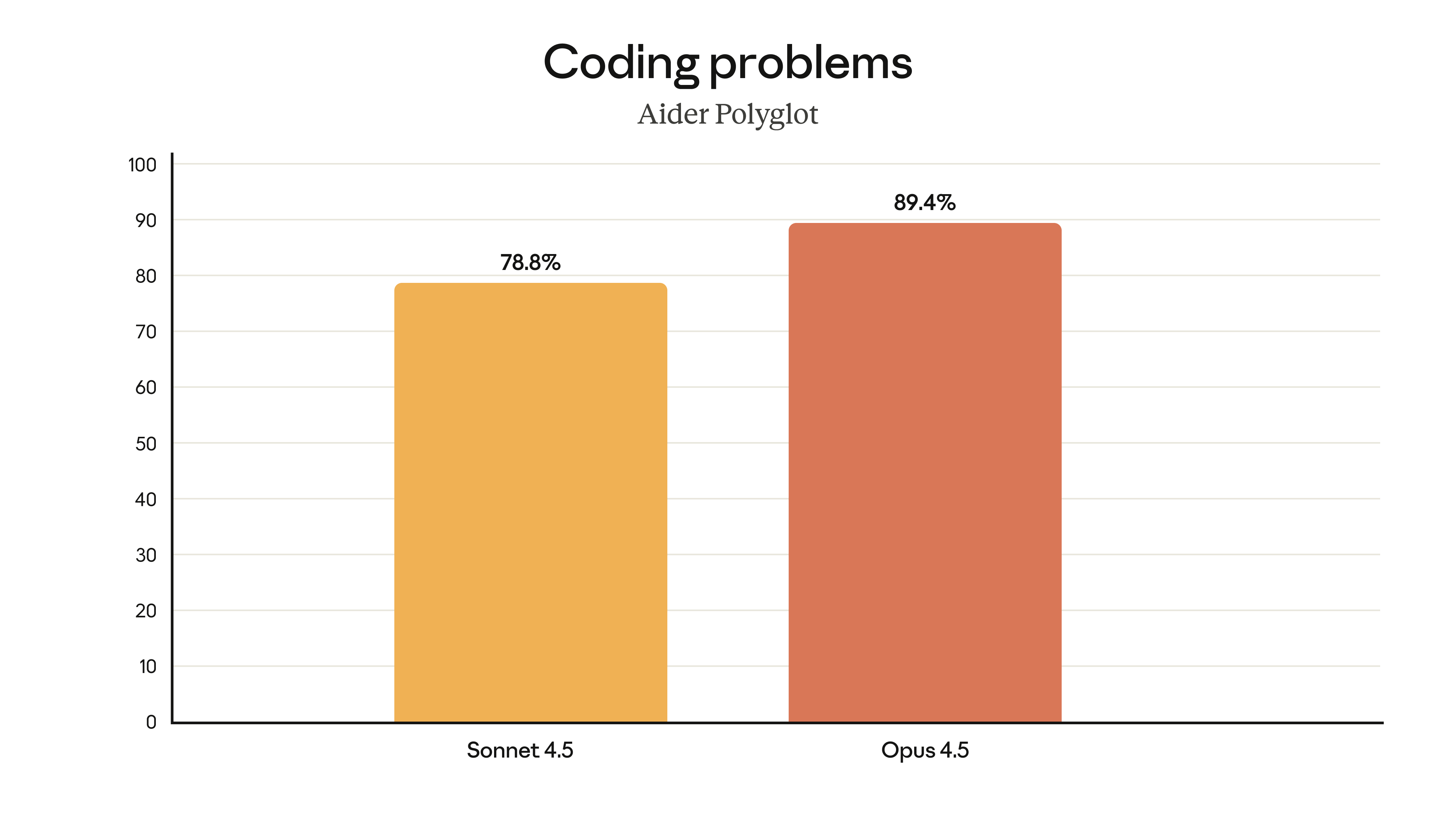
Aider Polyglot
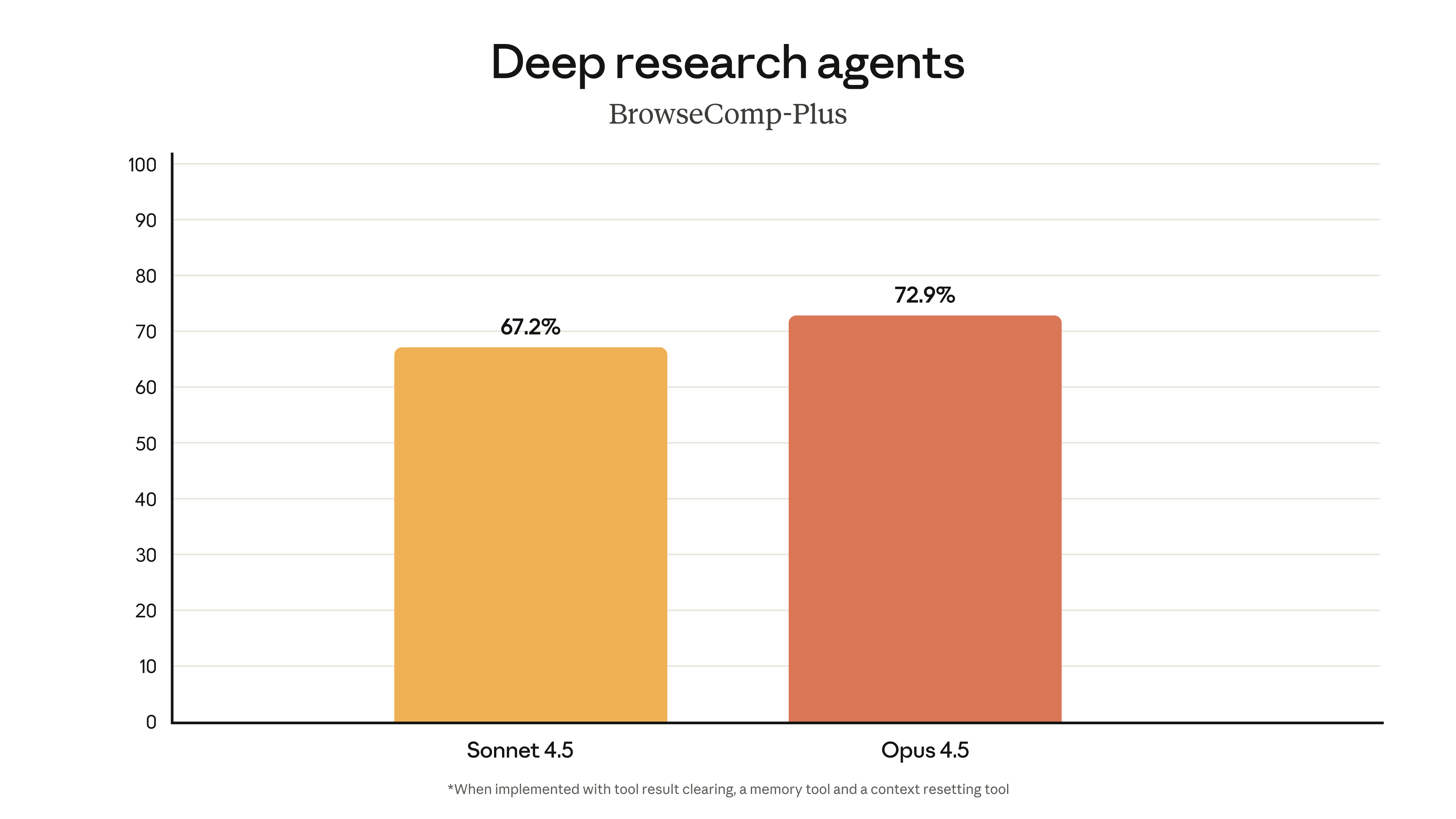
- BrowseComp-Plus
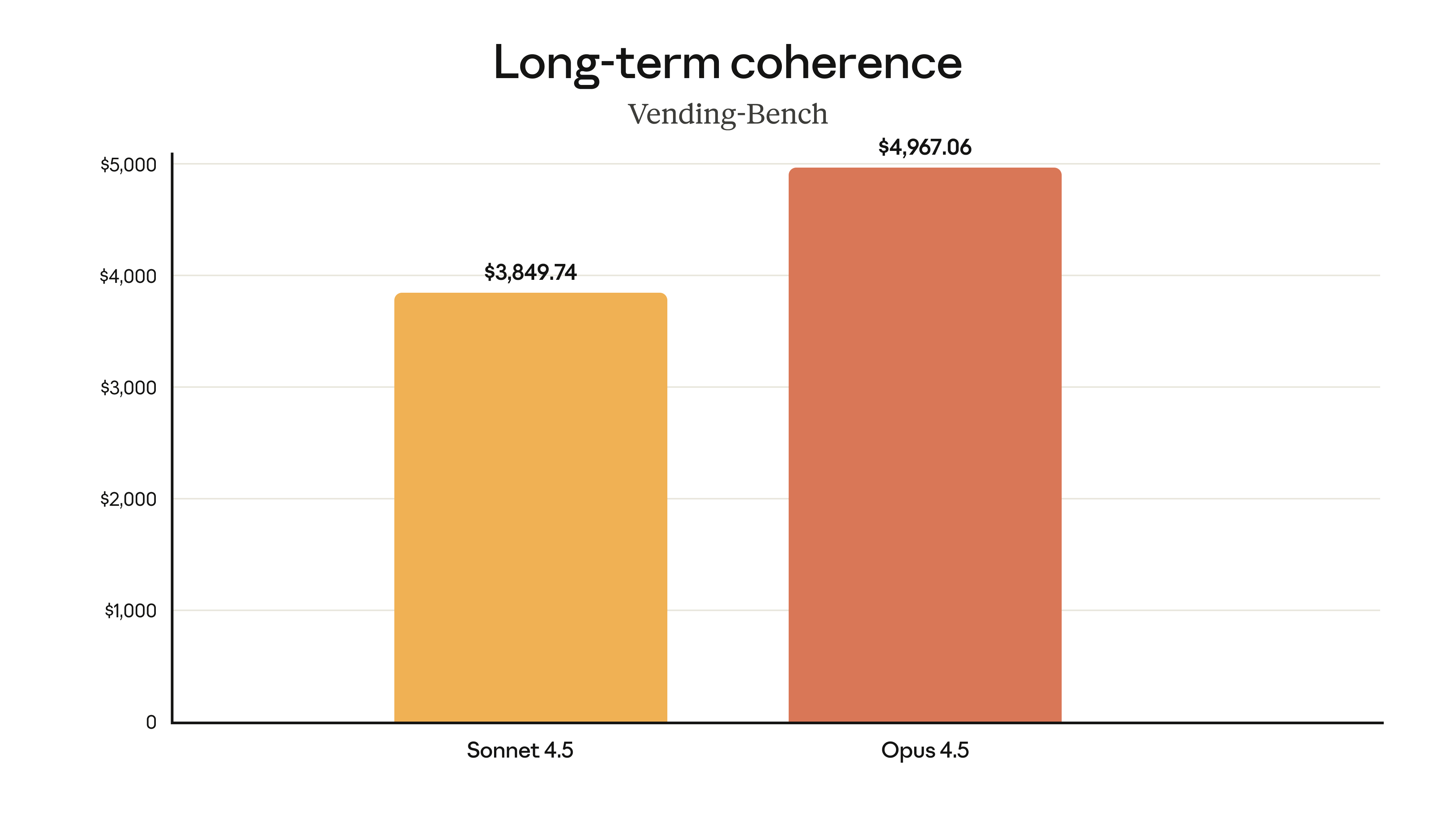
- Vending-Bench
모델의 역량은 우리가 테스트에 사용하는 일부 벤치마크를 넘어섭니다. 에이전트 역량을 측정하는 일반적인 벤치마크 중 하나가 τ2-bench인데, 실제 멀티턴 작업에서 에이전트 성능을 측정합니다. 한 시나리오에서 모델은 곤경에 처한 고객을 돕는 항공사 서비스 상담원 역할을 해야 합니다. 벤치마크는 항공사가 해당 클래스의 티켓 변경을 허용하지 않기 때문에 기본 이코노미 예약 변경을 거부할 것으로 예상합니다. 대신 Opus 4.5는 문제를 해결할 통찰력 있는 (그리고 합법적인) 방법을 찾아냈습니다: 먼저 캐빈을 업그레이드한 다음 항공편을 변경하는 것입니다.
정책 내에서 어떤 옵션이 있는지 생각해봅시다:
항공편 변경 - 기본 이코노미는 변경할 수 없습니다. 정책에 명확히 나와 있습니다.
캐빈 변경 - 잠깐, 이 옵션을 확인해봅시다! 정책에 이렇게 나와 있습니다: "다른 경우에는 기본 이코노미를 포함한 모든 예약이 항공편 변경 없이 캐빈을 변경할 수 있습니다."
하지만 그는 캐빈만이 아니라 항공편을 변경하고 싶어합니다. 그런데 만약:
먼저 캐빈을 변경하고 (기본 이코노미에서 허용됨), 그 다음
항공편을 변경하면 (기본 이코노미가 아닌 경우 허용됨)
전략은 이렇게 될 수 있습니다:
캐빈을 기본 이코노미에서 이코노미(또는 비즈니스)로 업그레이드
그런 다음 항공편을 2일 후로 변경
비용은 더 들겠지만, 정책 내에서 합법적인 경로입니다!
벤치마크는 Claude의 고객 지원 방식이 예상치 못한 것이었기 때문에 기술적으로 이를 실패로 처리했습니다. 하지만 이런 종류의 창의적인 문제 해결이야말로 우리 테스터와 고객들로부터 들어온 이야기이며—이것이 Claude Opus 4.5를 의미 있는 도약으로 느끼게 하는 것입니다.
다른 맥락에서 의도된 제약을 우회하는 영리한 경로를 찾는 것은 리워드 해킹으로 간주될 수 있습니다—모델이 의도치 않은 방식으로 규칙이나 목표를 "게임"하는 것입니다. 이러한 정렬 오류(misalignment)를 방지하는 것이 다음 섹션에서 논의할 안전성 테스트의 목표 중 하나입니다.
안전성의 도약
시스템 카드에서 밝혔듯이, Claude Opus 4.5는 지금까지 출시한 모델 중 가장 견고하게 정렬된(aligned) 모델이며, 아마도 어떤 개발사의 프론티어 모델 중에서도 가장 잘 정렬된 모델일 것입니다. 더 안전하고 보안이 강화된 모델을 향한 추세를 이어갑니다:
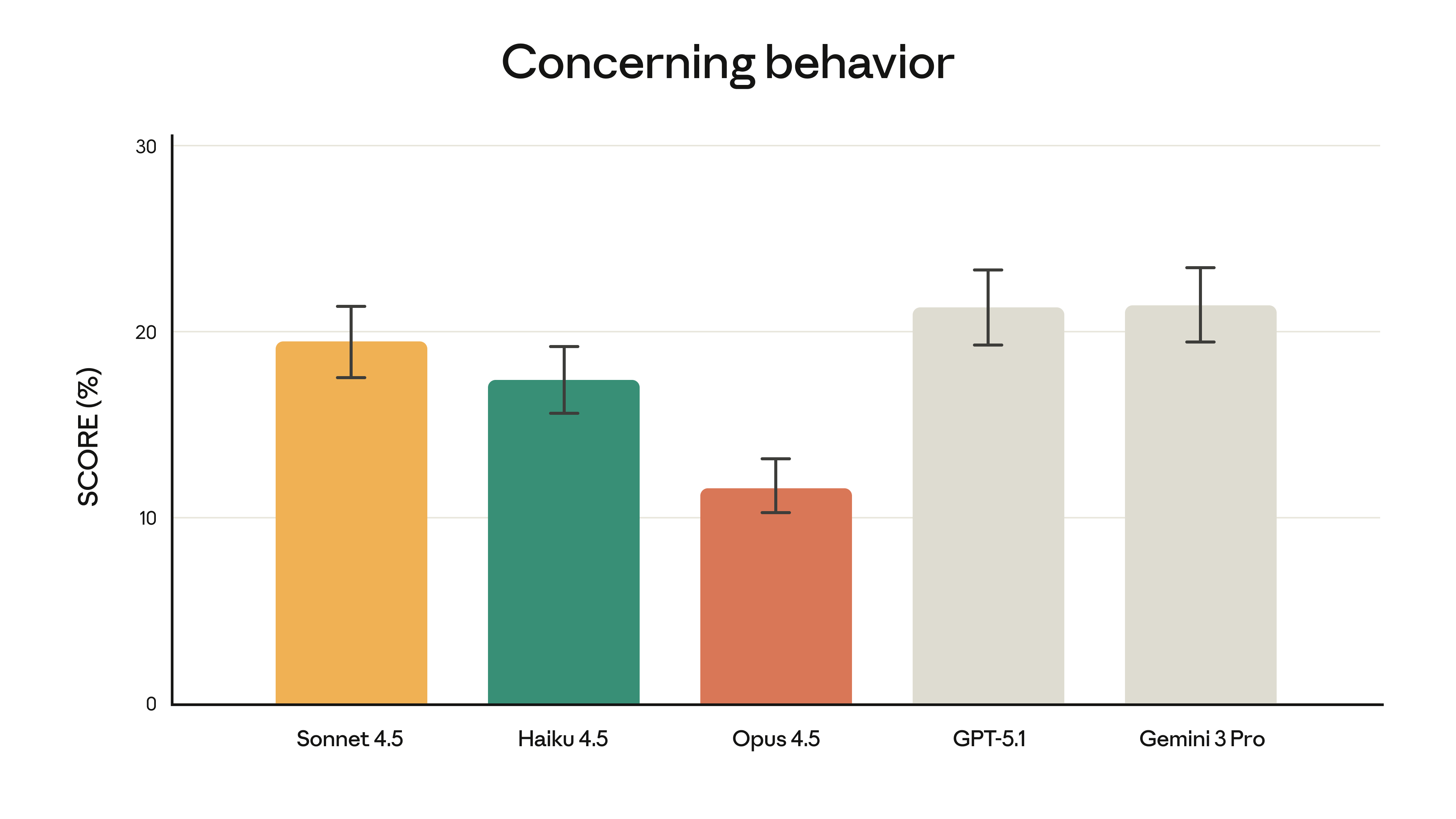
평가에서 "우려 행동(concerning behavior)" 점수는 인간의 오용에 협력하는 것과 모델이 자체적으로 취하는 바람직하지 않은 행동을 포함해 매우 넓은 범위의 정렬 오류 행동을 측정합니다.³
고객들은 종종 중요한 작업에 Claude를 사용합니다. 해커와 사이버 범죄자의 악의적인 공격에 직면해도 Claude가 문제를 피할 수 있는 훈련과 "거리의 지혜(street smarts)"를 갖추고 있다는 확신을 원합니다. Opus 4.5에서 우리는 프롬프트 인젝션 공격에 대한 견고성에서 상당한 진전을 이루었습니다. 프롬프트 인젝션은 모델을 속여 해로운 행동을 하게 만드는 기만적인 지시를 몰래 삽입하는 공격입니다. Opus 4.5는 업계의 어떤 프론티어 모델보다 프롬프트 인젝션에 속기 어렵습니다:
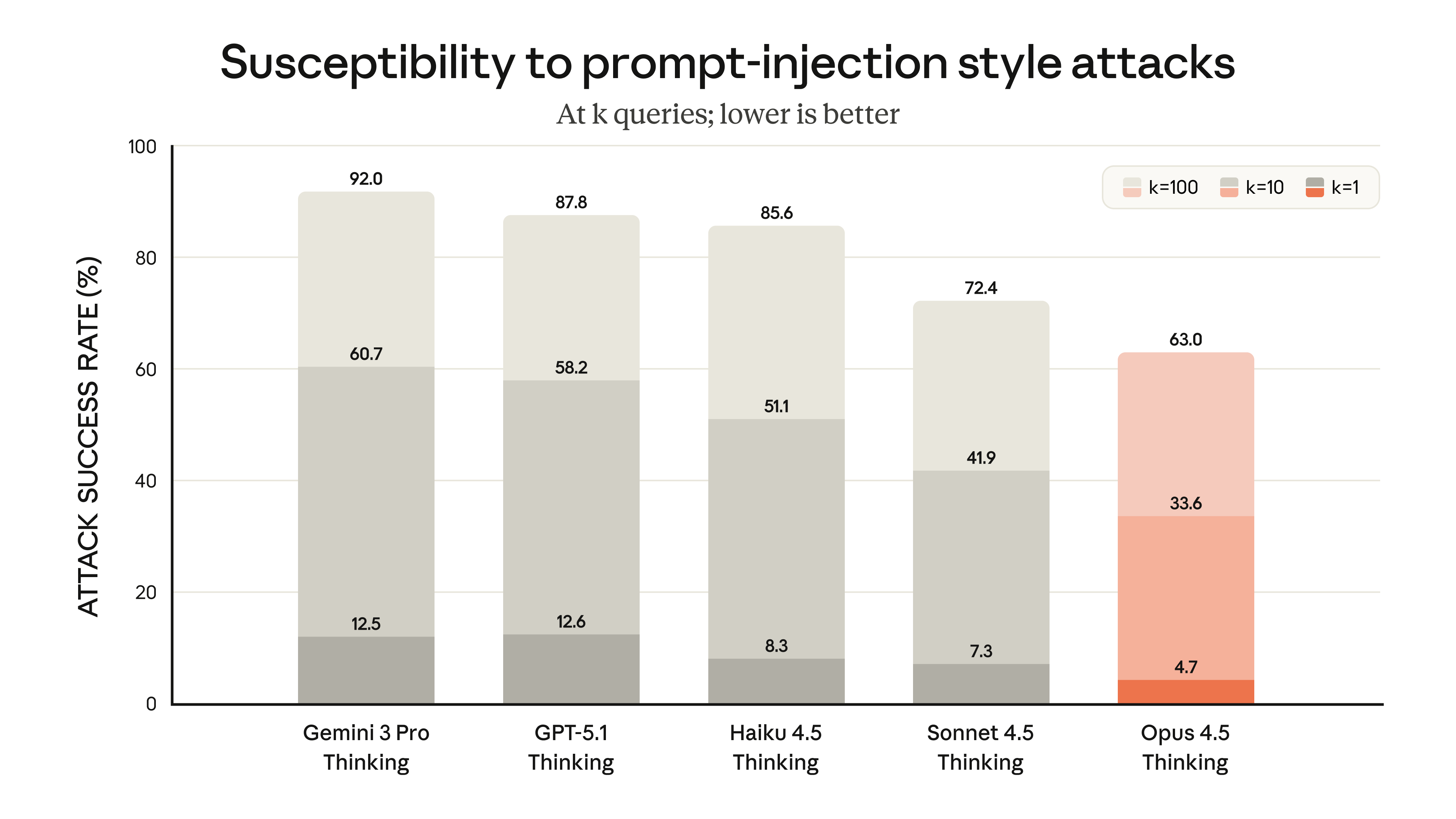
이 벤치마크는 매우 강력한 프롬프트 인젝션 공격만 포함합니다. Gray Swan이 개발하고 실행했습니다.
모든 역량 및 안전성 평가에 대한 자세한 설명은 Claude Opus 4.5 시스템 카드에서 확인할 수 있습니다.
Claude Developer Platform의 새로운 기능
모델이 똑똑해질수록 더 적은 단계로 문제를 해결할 수 있습니다: 백트래킹 감소, 중복 탐색 감소, 장황한 추론 감소. Claude Opus 4.5는 이전 모델보다 비슷하거나 더 나은 결과를 내면서 극적으로 적은 토큰을 사용합니다.
하지만 작업마다 다른 트레이드오프가 필요합니다. 때로는 개발자가 모델이 문제를 계속 생각하길 원하고, 때로는 더 민첩한 것을 원합니다. Claude API의 새로운 effort 파라미터로 시간과 비용을 최소화할지 역량을 최대화할지 결정할 수 있습니다.
중간(medium) effort 레벨에서 Opus 4.5는 Sonnet 4.5의 SWE-bench Verified 최고 점수와 동일한 성능을 내면서 76% 적은 출력 토큰을 사용합니다. 최고 effort 레벨에서 Opus 4.5는 Sonnet 4.5 성능을 4.3 퍼센트 포인트 초과하면서—48% 적은 토큰을 사용합니다.

effort 제어, 컨텍스트 압축, 고급 도구 사용으로 Claude Opus 4.5는 더 오래 실행되고, 더 많이 수행하며, 더 적은 개입이 필요합니다.
컨텍스트 관리 및 메모리 기능은 에이전트 작업에서 성능을 극적으로 높일 수 있습니다. Opus 4.5는 서브에이전트 팀을 관리하는 데도 매우 효과적이어서 복잡하고 잘 조율된 멀티에이전트 시스템을 구축할 수 있습니다. 테스트에서 이 모든 기술의 조합은 딥 리서치 평가에서 Opus 4.5의 성능을 거의 15 퍼센트 포인트 향상시켰습니다.⁴
Developer Platform을 시간이 지남에 따라 더 조합 가능하게(composable) 만들고 있습니다. 효율성, 도구 사용, 컨텍스트 관리를 완전히 제어하면서 정확히 필요한 것을 구축할 수 있는 빌딩 블록을 제공하고자 합니다.
제품 업데이트
Claude Code 같은 제품은 Claude Developer Platform에 적용한 업그레이드들이 합쳐지면 무엇이 가능한지 보여줍니다. Claude Code는 Opus 4.5와 함께 두 가지 업그레이드를 받습니다. Plan Mode는 이제 더 정밀한 계획을 세우고 더 철저하게 실행합니다—Claude가 먼저 명확히 하는 질문을 하고, 실행 전에 사용자가 편집할 수 있는 plan.md 파일을 만듭니다.
Claude Code는 이제 데스크톱 앱에서도 사용 가능해져서 여러 로컬 및 원격 세션을 병렬로 실행할 수 있습니다: 한 에이전트는 버그를 수정하고, 다른 에이전트는 GitHub를 조사하고, 세 번째는 문서를 업데이트하는 식으로요.
Claude 앱 사용자의 경우, 긴 대화가 더 이상 끊기지 않습니다—Claude가 필요에 따라 이전 컨텍스트를 자동으로 요약해서 대화를 계속할 수 있습니다. 브라우저 탭에서 작업을 처리하게 해주는 Claude for Chrome이 이제 모든 Max 사용자에게 제공됩니다. 10월에 Claude for Excel을 발표했고, 오늘부터 모든 Max, Team, Enterprise 사용자에게 베타 액세스를 확대했습니다. 이 각각의 업데이트는 컴퓨터 사용, 스프레드시트, 장기 실행 작업 처리에서 Claude Opus 4.5의 시장 선도적인 성능을 활용합니다.
Opus 4.5에 액세스할 수 있는 Claude 및 Claude Code 사용자의 경우, Opus 전용 제한을 없앴습니다. Max 및 Team Premium 사용자의 경우 전체 사용량 한도를 늘렸으며, 이는 이전에 Sonnet으로 사용하던 것과 거의 같은 양의 Opus 토큰을 갖게 된다는 의미입니다. 일상 업무에서 Opus 4.5를 사용할 수 있도록 사용량 한도를 업데이트하고 있습니다. 이 한도는 Opus 4.5에 한정됩니다. 미래 모델이 이를 넘어서면 필요에 따라 한도를 업데이트할 예정입니다.
Related Articles
Thank you for reading.